*모든 내용은 Hugging Face - Deep RL Course를 기반으로 작성하였습니다.
1. What is Reinforcement Learning?
강화 학습을 이해하기 위해, 큰 틀에서 강화 학습 개념에 대해 먼저 살펴본다.
The big picture
강화 학습의 기본 아이디어는 에이전트(agent, AI)가 환경과 상호작용(trial and error)하며, 행동으로부터 보상(negative, positive)을 얻으며 학습하는 것이다.
마치 현실에서 우리가 환경과 상호작용하여 배우는 것처럼 컴퓨터에게 이를 시키는 것이다.
예를 들어, 동생이 하나 있어 컴퓨터 게임을 한다고 해보자.

동생은 키보드를 누르며 환경과 상호작용을 할 것이고, 여러 개 누르다가 오른쪽 화살표를 누르는 순간 코인을 얻게 된다.
코인을 얻어 +1 만큼의 보상을 얻었고, 동생은 게임을 플레이하며 코인을 얻어야 함을 알게 된다.

그리고 다시 오른쪽 화살표를 누르면, 장애물과 부딪혀 죽게된다. 보상으로는 -1를 얻는다.

이렇게 환경과 상호작용하면서 동생은 적을 피하면서 코인을 얻어야 한다는 것을 이해하게 된다.
우리의 도움 없이도, 동생은 게임을 플레이하면 더 나은 행동을 하게 될 것이다!
A formal definition
정리하면, 강화학습의 정의는 이렇게 내릴 수 있다.
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
2. The Reinforcement Learning Framework
The RL Process

RL 프로세스를 이해하기 위해서, 플랫포머 게임을 하나 생각보면 쉽다.

- 에이전트는 환경으로부터 상태 $S_0$ 를 받는다 - 첫 게임 프레임이 나타난다(환경)
- 상태 $S_0$에 기반해, 에이전트는 행동 $A_0$를 취한다 - 에이전트가 오른쪽으로 이동한다.
- 환경은 새로운 상태 $S_1$으로 넘어간다 - 새로운 프레임으로 전환된다.
- 환경은 에이전트에게 보상 $R_1$을 준다 - 에이전트는 죽지 않았고 넘어갔다(보상+1)
즉, RL 과정에서 상태(state), 행동(action), 보상(reward), 그리고 다음 상태(next state)가 주어진다.

이렇게 에이전트의 목표는 특정 환경, 상태에서 행동을 취하며 받는 누적 보상, 기대값을 최대화 하는 것이다.
The reward hypothesis: the central idea of Reinforcement Learning
왜 에이전트의 목표가 기대값을 최대화 하는 것일까?
-> 강화학습은 보상 가설, 즉 모든 목표들이 기대값(기대 누적 보상)의 최대화로 설명될 수 있다는 것에 기반하기 때문이다.
-> 자동차 에이전트와 플랫포머 게임의 에이전트는 세세한 목표들이 다르다. 그러나 이 목표들은 강화학습 관점에서 행동에 따른 보상을 최대화 한다는 것으로 간주할 수 있다.
이를 강화학습은 the reward hypothesis에 기반한다고 말한다.
따라서 강화학습에서는 가장 좋은 행동을 하기 위해 기대값을 최대화하는 행동을 선택한다.
Markov Property
이 문서에서는 먼저 Markov Property 방식을 채택하여 진행한다.
Wikipedia에 적힌 Markov Property의 정의는 다음과 같다.
In probability theory and statistics, the term Markov property refers to the memoryless property of a stochastic process, which means that its future evolution is independent of its history. It is named after the Russian mathematician Andrey Markov.
미래에 대해 유추할 때, 현재의 값만을 사용하며 과거의 기록은 상관하지 않는 것이다.
마찬가지로 강화학습에서 Markov Property를 사용하게 되면, 현재의 상태만을 사용해 다음 행동을 취하며 과거의 상태들은 신경쓰지 않는다.
Observations/States Space
Observations/States Space는 에이전트가 환경으로부터 얻는 정보들을 의미한다. 비디오 게임으로 치면 프레임(스크린샷)으로 볼 수 있다.
Observation과 State에는 알아둬야 할 차이점이 있다.
State: 숨긴 정보 없이, 환경의 상태에 대해 완전히 알 수 있다.
ex) 체스, 체스보드의 모든 정보를 알 수 있다.

Observation: 환경의 상태에 대해 부분적인 정보만 알 수 있다.
ex) 슈퍼마리오, 특정 레벨 혹은 특정 장소에서의 환경만을 본다.

Action Space
Action Space는 특정 환경에서 가능한 모든 행동들의 집합을 나타낸다.
Action space는 다시 discrete(이산)와 continous(연속) space로 나뉜다.
Discrete: the number of possible actions is finite
ex) 슈퍼마리오에서는 4방향의 이동만 가지고 있기에 유한한 행동들의 집합을 가진다.
Continous: the number of possible actions is infinite
ex) 자율주행차에서는 무한한 행동들이 존재한다. 20도 좌회전, 21도 좌회전, 경적, 1m 전진 등등..
Rewards and the discounting
보상(reward)는 에이전트가 받을 수 있는 단 하나의 피드백이기에 강화학습에서 가장 핵심적인 부분이다.
이를 통해 우리는 좋은 행동인지 나쁜 행동인지 알 수 가 있다.
각 시간 간격 t에서의 누적 보상은 다음과 같이 쓸 수 있다.
$ R(\tau) = r_(t+1) + r_(t+2) + r_(t+3) + ... $
또한 이는 다음처럼 쓸 수 있다.
$ R(\tau) = \sum_{k=0}^{\infty} r_t + k + 1 $
그러나 현실 세계에서는 단순히 더할 수만은 없다. 다음 그림을 보자.
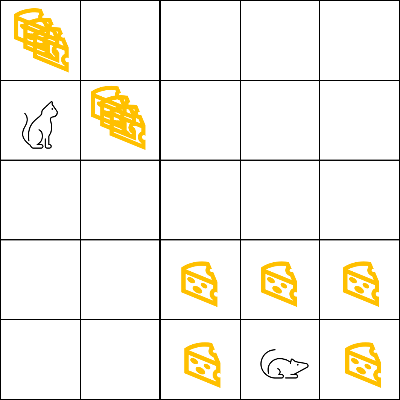
위 그림에서 쥐의 목표 고양이에게 잡히기 전에 최대한 많은 치즈를 먹는 것이다.
여기서 우리는 쥐 근처에 있는 치즈를 먹는 것이 고양이 근처에 있는 치즈를 먹는 것보다 더 낫다는 것을 알 수 있다.
왜냐하면 고양이에게 가까울 수록 더 잡힐 위험이 크기 때문이다.
따라서, 치즈가 많더라도 고양이에게 가까울 수록 보상은 더 작아지게 만들어야한다.
이를 할인(discount)라고 부른다.
보상을 discount하기 위해선 다음 방식을 진행한다.
1. 할인율(discount rate) 감마($\gamma, (0<=\gamma<=1$)를 정한다. 주로 0.95~0.99사이의 값이다.
- 감마 값이 커질 수록, 할인 폭은 작아진다. 즉, 에이전트는 장기적인 보상을 더 신경쓴다.
- 감마 값이 작아질 수록, 할인 폭은 커진다. 즉, 에이전트는 단기적인 보상을 더 신경쓴다.
2. 각 시간 간격 t에 대한 보상은 지수에 대 감마만큼 할인된다.
정리하자면, 우리의 할인된 누적 보상은 다음과 같이 쓸 수 있다.
$ R(\tau) = r_(t+1) + \gamma r_(t+2) + \gamma^2 r_(t+3) + ... $
$ R(\tau) = \sum_{k=0}^{\infty} \gamma^k r_t + k + 1 $
3. The type of tasks
Task는 강화학습에서 에이전트가 수행해야하는 작업이나 목표를 의미한다. Task에는 Episodic Task와 Continuing Task, 두 가지 종류가 있다.
Episodic Task: 시작 지점과 끝 지점이 있다. 하나의 에피소드를 만들듯이 States, Actions, Rewards, 그리고 new States를 만 들어낸다.
ex. 슈퍼마리오, 시작은 새로운 레벨 실행했을 때이고 끝은 죽었거나 도착지점에 도달했을 때
Continuing tasks: 시작 지점과 끝 지점이 없어 계속 진행된다.
ex. 주식 트레이드, 우리가 멈출 때까지 에이전트를 계속 실행한다
4. Exploration/Exploitaion tradeoff
Exploration/Exploitation은 강화학습에서 에이전트가 어떻게 학습해 나가는지를 설명하는데 사용한다.
Exploration(탐험): 랜덤으로 탐험하며 행동하는 방법으로, 환경에 대한 정보를 더 많이 얻기 위한 방법이다.
Exploitation(활용): 이미 알고 있는 정보를 토대로, 보상을 최대화 하기 위해 나아가는 방법이다.
강화학습에서는 이 Exploration과 Exploitaion의 균형을 맞추는 것이 중요하다.
다음 그림을 예시로 들자.

위 그림에서, 쥐 주변에는 작은 치즈(+1)가 무한으로 있고 멀리 있는 곳에는 큰 치즈(+1000)가 있다.
만약 우리가 exploit만 하게 된다면, 저 멀리 있는 치즈는 신경쓰지 않고 가까이에 있는 치즈만 신경쓰게 된다.
그러나 우리가 explore를 한다면 먼 곳으로 탐험해 더 많은 치즈를 얻을 수 있다.
이렇게 exploit과 explore간의 밸런스를 맞추는 것을 exploration/exploitaion trade-off라고 한다.
5. Two main approaches for solving RL problems
어떻게 해야 기대값을 최대화 시키는 행동을 하게 에이전트를 만들까?
The Policy π: 에이전트의 뇌. 현재 상황, 특정 시간에 에이전트가 어떻게 행동할 지를 정한다.
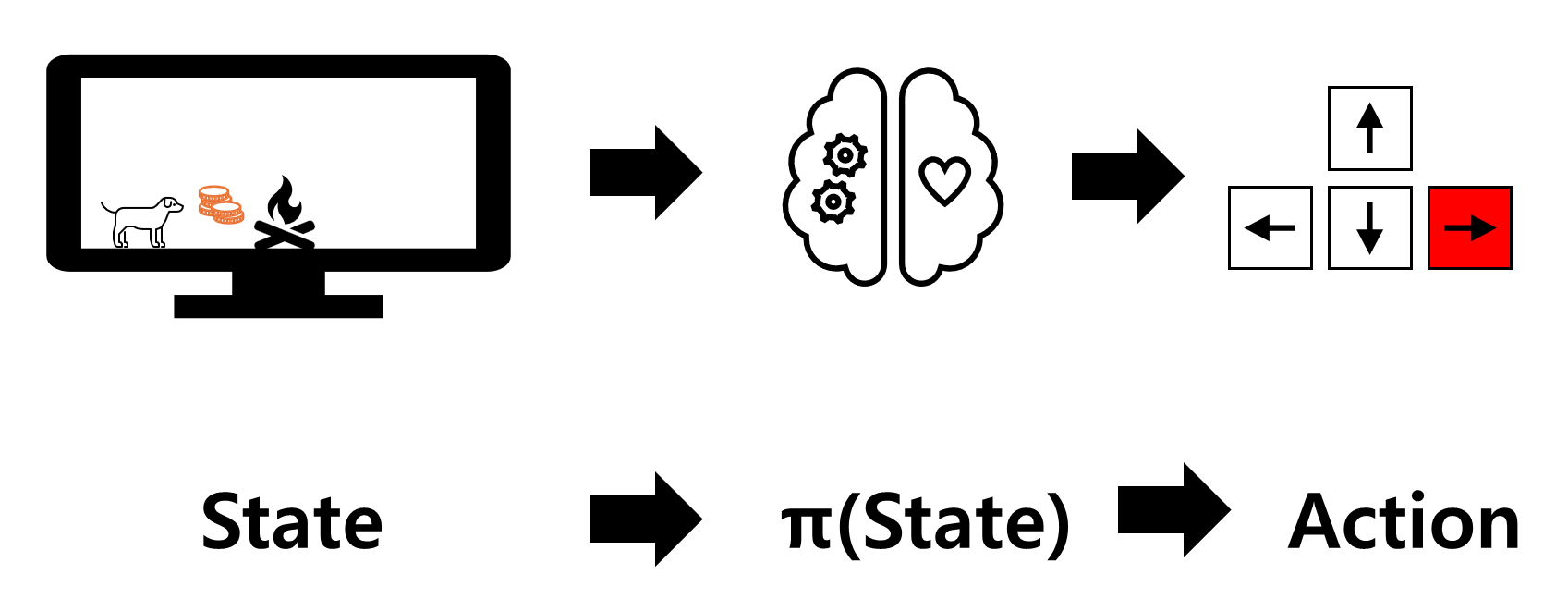
우리가 원하는 최적의 에이전트를 만들기 위해서, 가장 최적의 optimal policy π *를 찾아야 한다.
Optimal policy π*를 찾는 방법에는 두 가지가 있다.
Policy-based method
: 에이전트에게 어떤 행동을 할 것인지 직접 가르친다.

위 그림에서는 강아지에게 특정 상황에 어떤 방향을 갈 지 알려주고 있다.
Policy based metho의 policy는 두 가지 타입이 있다.
Deterministic: 특정 상태에 항상 같은 행동을 한다. $a = \pi(s)$

Stochastic: 특정 상태에 대한 행동의 조건부 확률을 나타낸다. $\pi(a|s) = P[A|s]$ 즉, 특정 상태에서 어떤 행동을 할 확률을 알려준다.

Value-based method
: Value function을 사용 expected discounted return을 나타낸다.
$𝑣_\pi (𝑠) = 𝐸_\pi [(𝑅_(t+1)+ 𝛾𝑅_(t+2) + 𝛾^2 𝑅_(t+3) + ⋯ |𝑆_t = 𝑠]$

이후 챕터에서는 강화학습의 방법 중 하나인 Q-learning에 대해 알아보고 google colab으로 scratch부터 구현한다.
개인적으로 custom environment를 만들어 테스트도 진행해보려 한다.
'인공지능' 카테고리의 다른 글
| 딥러닝 공부 - 1 (1) | 2023.11.29 |
|---|